There is increasing concern over the repeatability and reproducibility of computational science (see also here, here, here, here and here). If computational scientific enterprises want to be accumulative more transparency is required including the archiving of computer code in public repositories. This also holds for agent-based modeling, an increasingly popular methodology in the social and life sciences.
I show here some initial results of an analysis of the practice of archiving agent-based models. Five journals were selected that regularly publish research that use agent-based models: Advances in Complex Systems, Computational and Mathematical Organization Theory, Ecological Modelling, Environmental Modeling and Software, Journal of Artificial Societies and Social Simulation. Using the ISI web of science we searched for all articles in those 5 journals in the years 2010 to 2014 using the search term “agent-based model*”. This resulted in 255 articles on September 5, 2014 of which 56 articles were disregarded since they did not discuss an agent-based model itself.
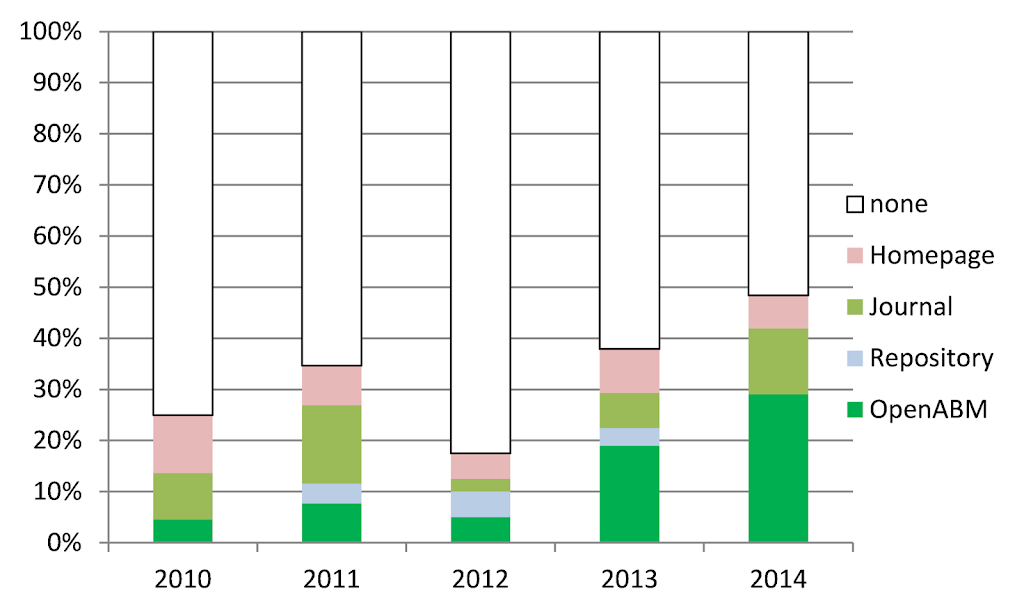
Out of the 199 remaining articles 135 were found not to provide the computational model’s source code. 21 articles referred to an institutional or individual homepage. In 5 cases, the link resulted in a 404 not found error and we recorded that the code was not available. In 17 cases the code was included as an electronic appendix of the journal. Only 31 articles provided the model code in a public archive, out of which 26 were stored at the CoMSES Computational Model Library . The other 5 models were archived in repositories like Bitbucket, Git Hub, Google code, Sourceforge and the Netlogo community models site.
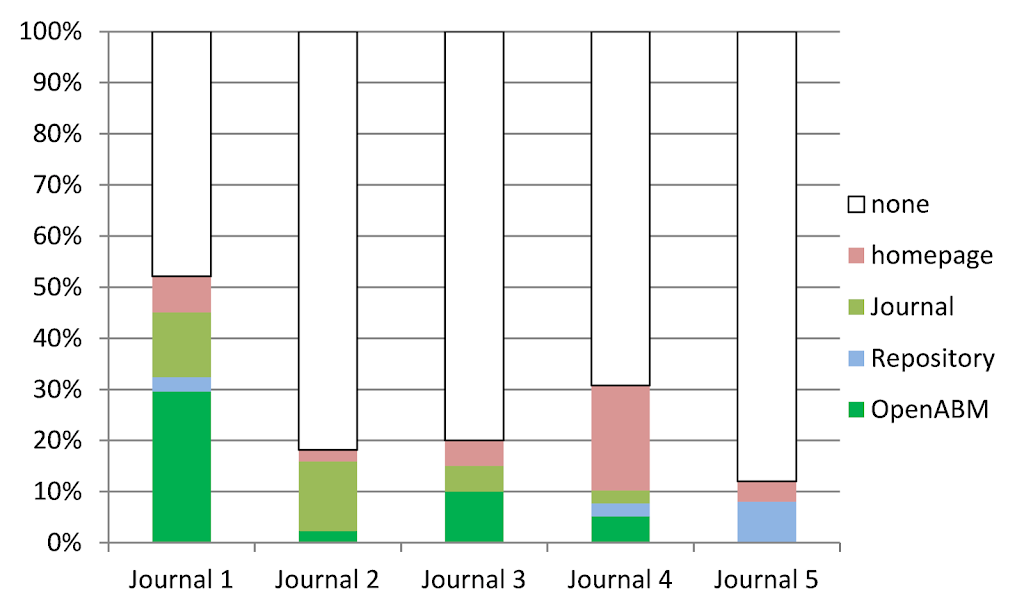
Over the years there has been improvement in model archiving. In 2010 75% of models were not archived. The increasing availability of public archives has enabled authors to archive their models more frequently and in 2014 50% of the models are archived. The majority of those models are archived in OpenABM. As we can see, most models are still not archived. One journal has championed model archiving with more than 50% of its publications associated with a publicly archived model, whereas the other journals have an archiving percentage between 10% and 20%.
Since most research is sponsored by tax money, sponsors sometimes explicitly require that the data, including software code, is made publicly available. We find that papers from the 2 main sponsors (16 by European Commission and 21 by the National Science Foundation) experience a low compliance rate to best practices. In both cases we find that only 15% of the models are available in public archives, significantly lower than the articles that do not list a sponsor (29%), or list other sponsors (24%).
Currently the scope of the analysis is extended to about 3000 articles (using search term agent-based model* unrestricted to years and journals). Besides getting a better picture of current archiving practices we also hope this activity lead to more awareness of the problem and the need for journals to increase requirements for archiving code and documentation in public repositories.